With the recent AI fad, there is something that has caught my attention: RAG systems. (I will let you research what these are yourself; any explanation here will just be redundant and most likely will not be exhaustive anyway.) The part that interests me is that, if I were to ask a question about a topic that one of my books contains, hopefully the system will be able to answer. Why don’t I just ask Copilot or OpenAI or this or that? Well, sure I can. However, I came up with an idea that will, as they say, kills two birds with one stone. I can both learn something about the components of a RAG system and also implement something that is useful to me.
I gave myself a personal assignment: implement a RAG system that will hunt down different text documents on my computer and feed them to the system so that I can then just ask questions. If a question is found from any of the documents I fed into the system, then it would answer without me having to search my “library” of docs to see if any of them had the answer. For now, I would focus on only the answer. I decided not to include breadcrumbs to the “source” of the answer. But that was something I could see being useful to add later.
There are several components of a RAG system that I had to put into place:
- Content extraction — given all the different content formats (e.g. PDF, ePUB, TXT, Word, as well as others), there needs to be a way to extract the text contents into manageable chunks to be fed into the system and recalled from the system.
- Embedding generation — lookups can be done several ways. The old way was an inverted index search (e.g. Solr or Elasticsearch). The RAG trend favors (at least mainly) a type of semantic search using embedding vectors for a chunk of content. Therefore, these vectors need to be generated. These vectors, of course, should represent semantically the content they are generated from so that we can query for them.
- Embedding storage — some data store to put all the generated vectors and associated content and metadata so that they can be managed and recalled correctly.
- Answer generation (nice to have?) — once the relevant contents are recalled given a prompt, it’d be nice to be able to generate an answer to the original prompt question. I say this is “nice to have” because I can argue that having the recalled contents and associated metadata may be good enough for me–because I can then go to the actual document(s) and read up on my own. That would in return serve two purposes:
- Allows me to make use of the document to get more detailed information on the topic.
- Ensure that the answer generated isn’t an error (aka “hallucination”).
Content Extraction
Scanning subdirectories on a local file system is straight-forward. Any newbie with an understanding of recursion can code that up. Heck, even AI can generate a routine for that.
The extraction of content from various file types takes a bit more work. Fortunately, Python has libraries for most:
- PDF — pypdf
- ePUB — this one turned out to be more work that I expected. I didn’t find a handy library to incorporate into my project, so I ended up coding up one using xmltodict (to navigate the document hierarchy and metadata) and BeautifulSoup (to extract the actual text content).
- On some previous work with ePUB, I learned that it’s basically a ZIP file of a set of HTML, CSS, and XML documents. This makes working with them a lot more straight-forward.
- txt — this one is easiest, of course.
- Microsoft Word — I didn’t think I’d get this one since I remember the format is proprietary and binary (more painful to work with than with ePUB). However, there is docx, and I’ll take it as far as it gets me.
As for chunking and metadata handling, some straight-forward coding will achieve that. There has to be some coding for it to be fun, after all. Otherwise, I might as well go sit and watch TV.
Embedding Generation
Something I cannot code up by myself, however, is a model to regress vectors for chunks of text. This is where the initial phase of learning and research starts.
After some searching and messing around, I chose to use the sentence-transformers library (started with the model “all-MiniLM-L6-v2” but since switched to “BAAI/bge-large-en-v1.5“).
An embarrassingly thin wrapper (SentenceTransformersEmbeddingService) was created around the library to generate embeddings for a chunk of text. Just so if I need to change implementation (e.g. the embedding model), there’s some encapsulation (BaseEmbeddingService) to protect downstream rework.
This thin wrapper is available from vembedding-generation.
NOTE: as of now this repo is private. I will make it public once I’m happy with its status.
Embedding Storage
After the vectors are generated, I need some vector DB to store them along with metadata (and content if supported) AND to be able to query them using some kind of similarity search.
With the popularity of AI (and RAG), there are many choices here. Chroma DB came to mind. However, I’m unemployed, so I don’t have a lot of money to throw around. I know they have a “local” version to work with, but they really are aiming for me to use their cloud storage with a $ubscription.
I have some experience working with PostgreSQL in the past. And with the pgvector and its related Django binding, I think I have what I need for the time being (for free).
Oh. This would be a good time to go over the architecture.
Since I envision this system to be interactive eventually, some kind of GUI would be nice. And as for the text extraction, vector generation, and querying for that matter, might be asynchronous operations, I’m looking at a Django app with Celery. And since I’m looking at PostgreSQL, it just so happens Django works with PostgreSQL (via psycopg) pretty well.
Again, there is some schema noodling to accommodate a flexible design that supports different variations in case I need to play around. I’d rather not have to tear down and create a new table/schema each iteration. This is where I actually had a pretty good “vibe” session with Copilot to come up with a design.
The result is my vembedding-store-pg library. It again has an abstraction service class (EmbeddingStorageService) to shield the underlying PostgreSQL implementation in case I do want to go back to something like Chroma DB or something. NOTE: as of now this repo is private. I will make it public once I’m happy with its status.
Always design for options.
So far, this is where things are:
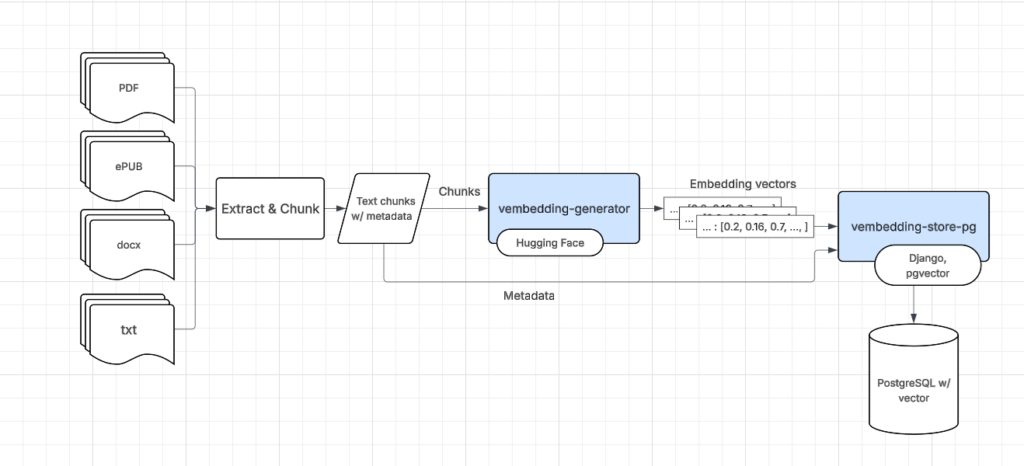
The blue blocks are libraries I pulled out into separate packages that can be reused hopefully in other things I will do in the future.
Query
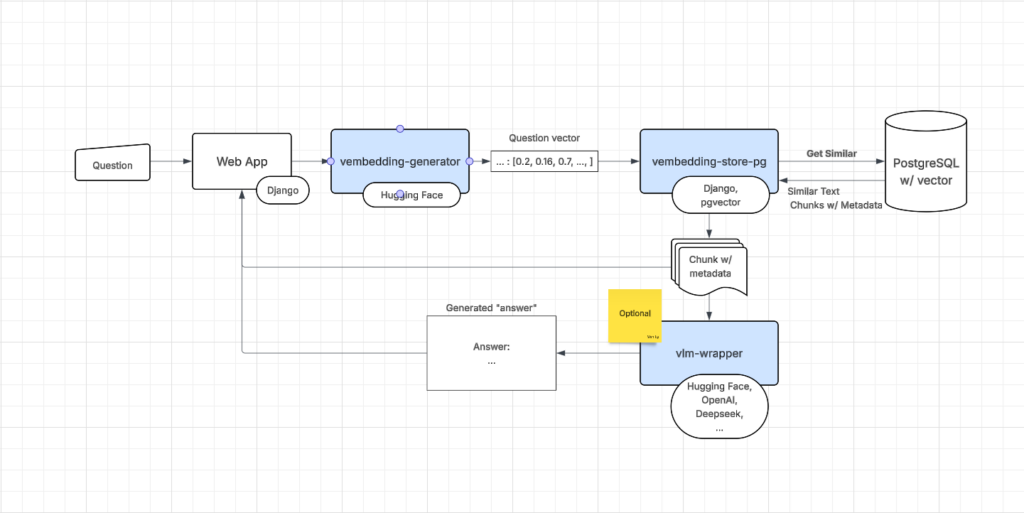
As mentioned, once everything is set, the payback is that I can type in a question that can be answered from the documents ingested into the system previously, and the system will return a list of text chunks that have the answer. More accurately, it will return text chunks that are semantically similar to my question.
From the text chunks and their metadata such as information about the original documents they were extracted from, I can quickly open up the corresponding document and find the answer.
The sequence goes like this:
- I ask a question about something that hopefully a document ingested has an answer to.
- The question’s embedding vector is calculated.
- The vector is passed to the system to find similar vectors corresponding to the text chunks ingested.
- The text chunks are looked up and returned to me, along with the metadata for each, sorted in order of relevance.
Answer Generation
Ah yes. This is where the GPT comes into the picture. So many competing choices. All Most of them cost money.
After some more research and messing around, I was able to get something working that is free: using the “mistralai/Mistral-7B-Instruct-v0.2” model with the transformers library, also from Hugging Face.
I’d be first to admit that I’m still quite thoroughly confused about the whole ecosystem. Reading the README.md of transformers confuses me more than helps me. Therefore, I’m looking at the entire situation as I do with driving my automatic: I know how to use the power steering and automatic transmission of the car while having no idea how they work. I may have time and opportunity to learn more about this AI frontier (e.g. using torch and/or deep learning). I’ll even settle with being able to work confidently with the pipeline construct.
As of now, again, I have a thin wrapper around different GPTs/models to serve as the generative part that spits out an English answer to the similar texts found for a question. There is an abstract base class AnswerCompositionService which has the template for different implementations:
HuggingFaceAnswerCompositionServicewhich uses the transformers library as described above. This is the only “free” and local model option for now.OpenAiAnswerCompositionServicewhich uses the cloud services OpenAI and DeepSeek offer. DeepSeek shrewdly adopts the OpenAI API/convention with a few configuration changes (i.e. URL and model names), so it wasn’t difficult to add support for it at all once the code worked with OpenAI.
And this is all in my vembedding-lm library. NOTE: as of now this repo is private. I will make it public once I’m happy with its status.
This is what the query and generation part look like:
Demo!
So I downloaded a copy of the U.S. Declaration of Independence document from the National Archives, saved it as a PDF, then extracted and chunked the text, got the embeddings from the chunks, stored them into PostgreSQL, then asked some questions by running the question through the same embedding to get a vector to then find similar texts from, and finally fed the found texts to the LM to generate answers.
Currently, this is all done via the Django shell invoking the classes directly. Someday this flow may be supported with a nice GUI, possibly even written in React or Vue.js.
Question:
What is the Declaration of Independence attempting to declare independence from?
Answer:
The Declaration of Independence is attempting to declare independence from Great Britain.
Question:
Who ruled Great Britain?
Answer:
The present King of Great Britain is referred to in the context.
However, the name of the king is not mentioned. Therefore, an answer cannot be
definitively determined based on the context alone.
Question:
How many states were there when the declaration of independence was drafted?
Answer:
Thirteen states were represented when the Declaration of Independence was drafted.The above was using the Hugging Face library with the model all-MiniLM-L6-v2. Not bad so far! I was delighted that the model respected the prompt to limit its source material only to the context given. Otherwise, I’m certain that it would’ve looked up the British king at the time. (By the way, boys and girls, that would be King George III according to Copilot.)
It was taking minutes to generate the answer, even though the PostgreSQL look-up was almost instanteous. Most likely it’s because I was running this all in Docker on my 2018 Intel MacBook Pro.

Next episode: https://snippets.therealvan.com/2026/05/14/rag-ingesting-model/